Эта статья имеет только рекомендательный характер т.к. обычно каждый системный администратор самостоятельно решает какие именно параметры ему интересны и какими инструментами производить мониторинг.
Цитата из документации:
В состав платформы входят следующие экспортеры:
- rabbitmq-exporter (kbudde/rabbitmq-exporter) – сбор метрик брокера сообщений RabbitMQ. Список доступных метрик.
- nginx-exporter (nginx/nginx-prometheus-exporter) – сбор метрик контейнера proxy. Список доступных метрик.
- redis-exporter (oliver006/redis_exporter) – сбор метрик контейнера redis. Список доступных метрик.
- postgres-exporter (prometheuscommunity/postgres-exporter) – сбор метрик контейнера postgres. Список стандартных метрик.
- cadvisor (gcr.io/cadvisor/cadvisor) – сбор метрик контейнеров docker. Список доступных метрик.
- node-exporter (prom/node-exporter) – сбор метрик виртуальной машины. Список доступных метрик.
И еще:
По умолчанию мониторинг выключен. Чтобы его включить, необходимо в файле
inventory/[single,distributed]/group_vars/all/monitoringизменить значение переменной monitoring_enabled на true.
При этом заполнить следующие переменные:
- monitoring_external_labels – дополнительные метки для метрик мониторинга, принимает в качестве значения list;
- vmagent_remote_write_address_list – адрес, на который будут передаваться метрики, принимает в качестве значения list (по шаблону, указанному в файле);
- vmagent_remote_write_port – порт, по которому будут передаваться метрики;
- vmagent_auth_enabled – необходимость авторизации в prometheus;
- vmagent_auth_ssl_enabled – использование ssl;
- vmagent_basic_auth_user_insert – пользователь для prometheus;
- vmagent_basic_auth_pass_insert – рандомный пароль для Prometheus, заполняется вручную в соответствии с принятой в компании парольной политикой;
- rabbitmq_exporter_user – имя пользователя для сервиса rabbitmq; значение должно совпадать со значением переменной
rabbitmq_default_userв файлеinventory/[single,distributed]/group_vars/all/vars.- rabbitmq_exporter_password – пароль для сервиса rabbitmq; значение должно совпадать со значением переменной
rabbitmq_default_passв файлеinventory/[single,distributed]/group_vars/all/vars.
На практике:
В нашей инфраструктуре для мониторинга мы используем связку из Icinga + Grafana, но думаю вам больше интересно что именно мы мониторим.
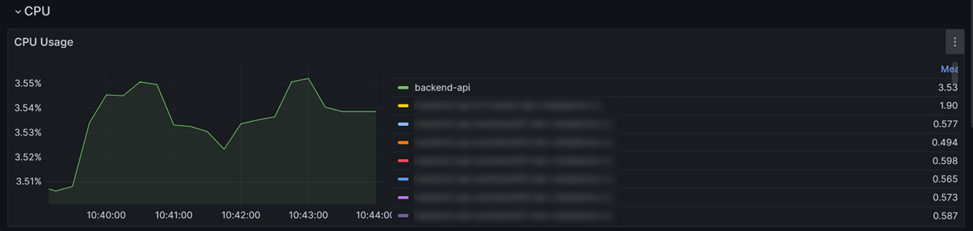
И первое что нам интересно это утилизация CPU контейнерами. Исходя из этих показаний мы можем понимать какой контейнер у нас потребляет больше ресурсов. Это полезно при расследовании инцидентов и уже не перебирать логи всех контейнеров подряд, а только того, кто больше всех потреблял.
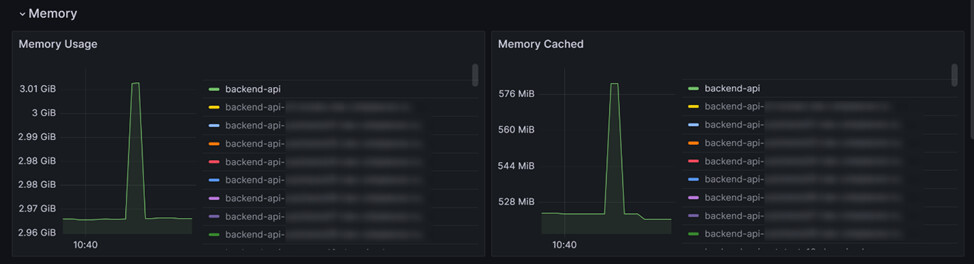
Memory – тут все тоже самое что с CPU.
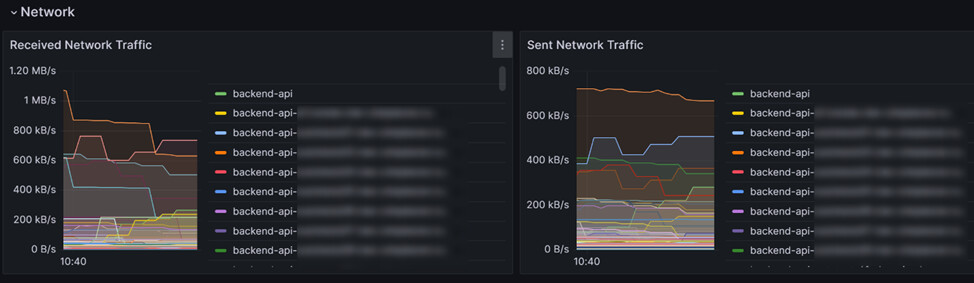
Network бывает полезно при большом количестве интеграций.
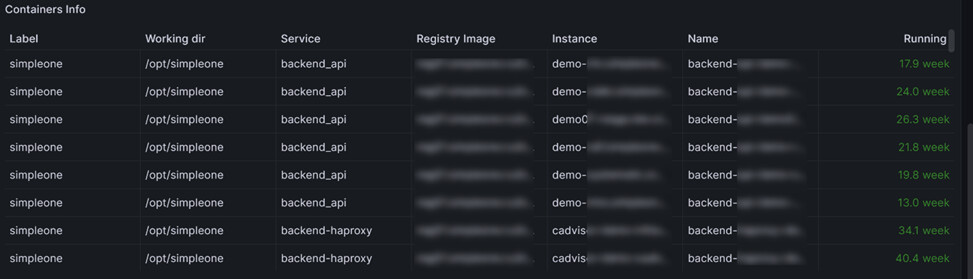
Состояние контейнеров – тут думаю пояснение не требуется. Крайне важно знать состояние и вовремя восстановить работоспособность системы. Особенно это актуально для распределенных систем. Например, у вас может не работать половина кластера, а пользователи ничего не заметят.
Мониторинг PostgreSQL это отдельная вселенная, которая требует консультаций с администраторами БД.
По мимо приведенных выше параметров есть и другие (например: утилизация: дисков, IOPS и т.д.), но они уже относятся к самой инфраструктуре и не имеют прямого отношения к мониторингу SimpleOne.