Всем привет, поделитесь реальным опытом, у пользователя будет несколько принадлежностей к сущности, похожей на компании, что лучше использовать M2M таблицы или List. List конечно визуально гораздо лучше смотрится, но исходя из хранения данных в поле типа List(значения, через запятую) мне кажется, что могут быть проблемы с производительностью при фильтрации по данному полю.
Привет!
Преимущества M2M таблицы
а) Фильтрация по dot-walking полям в M2M легче, например, "покажи мне все записи M2M, где “сущность, похожая на компанию”.Active = false, c List полем придется пробегаться по всем значениям массива в поле, тоже быстро, но придется поскриптовать
б) Загрузка данных через Import Set легче в M2M таблицу - смапил поля и готово
Недостатки M2M таблицы
Нужно создать пару бизнес-правил, чтобы не допустить полные дубликаты (пользователь - “сущность, похожая на компанию”) в M2M таблице, но это работа на полчаса.
Преимущества List поля
а) Быстрая реализация и визуально понятно конечному пользователю, но про репортинг и фильтрацию по значениям этого поля придется либо забыть, либо скриптовать
б) Через UI туда невозможно добавть дважды одну и ту же сущность.
в) Можно бизнес-правилом или клиентским скриптом анализировать изменения (что удалили или что добавили или и добавили, и удалили), если изменения поля идут через UI и принимать какие-то решения. Это редкий случай.
Лично я бы пошел через List поле, если априори не нужно репортить по данным из этого поля или как-то его мейнтейнить, то есть поле хранит какие-то данные, по которым нет фильтрации или репортига.
Гибрид
Можно пойти по гибридному пути - мейнтенить (создавать, изменять, удалять) записи в M2M таблице, а для визуализации (если по какой-то причине связанный список не катит) собирать List поле из M2M записей с помощью onInsert, onUpdate, onDelete бизнес-правил на M2M таблице. Реальных причин это делать нет. На худой конец можно пойти по M2M пути и визуализировать записи M2M на форме пользователя через красивенький виджет.
С уважением,
Никита
3 лайка
подскажите, есть ли возможность на поле List сделать индекс чтобы не было полного скана таблицы, учитывая, что данные в поле List хранятся, как значения через запятую, не очень понятно как буде работать выборка по этому полю
Андрей, привет!
Как освобожусь, попробую глянуть, что происходит на уровне SQL при запросе по “List column” has value. Есть подозрение, что на уровне SQL там все хорошо и индекс SQL не требуется, но не уверен до конца.
У Вас наблюдается проблема с производительностью на больших объемах данных при таких запросах?
С уважением, Никита
1 лайк
Добрый день, вопрос больше возник из того, как S1 работает внутри, чтобы понимать какие механизмы использовать при проектировании решений.
Андрей, к сожалению, не смогу быстро проконсультировать по работе на уровне SQL в S1, надо подучить матчасть по Postgres.
Если Вы являетесь представителем партнера или клиента S1, то можете открыть инцидент с вопросом для получения профессионального ответа касательно необходимости создания индексов на колонках с типом “list”. По моему тесту на 100К записях этого не требуется (см. ниже).
На данный момент я провел тест на своем sandbox (с небольшим количеством ресурсов): создал 120К записей в таблице Task [task] в рандомными значениями в list поле “Followers list” и последовательно, пока таблица наполнялась тестовыми записями, делал запросы типа “Followers List” has {Value} (на 100, 1000, 10000, 50000, 100000 записях) - ответ всегда приходил в течение 1 секунды.
Изучу при первой возможности, как получить exec план SQL Query на Postgres, но это займет некоторое время, поэтому быстрого дальнейшего ответа от меня прошу не ожидать.
С уважением, Никита
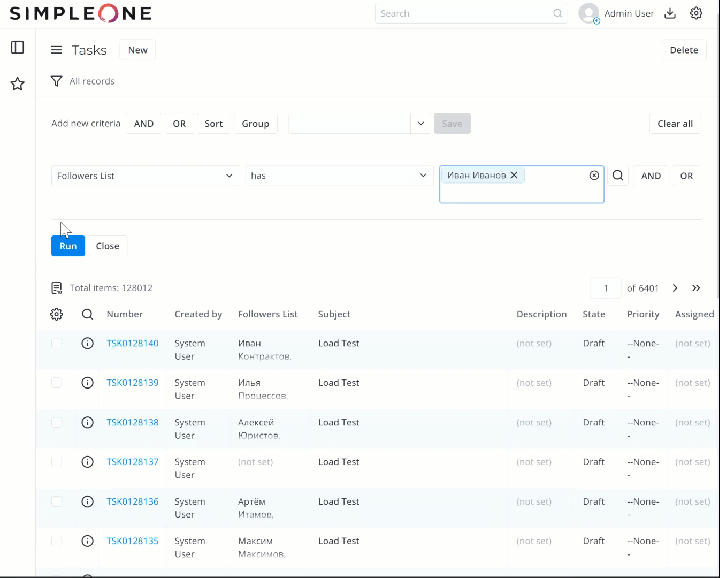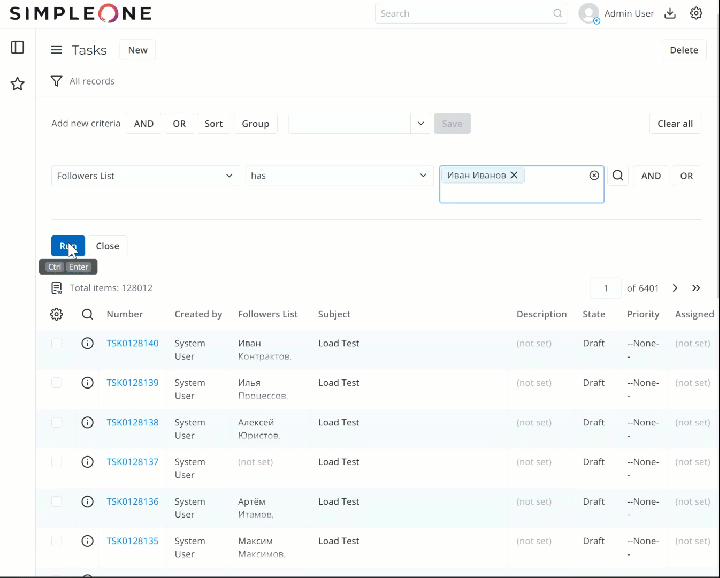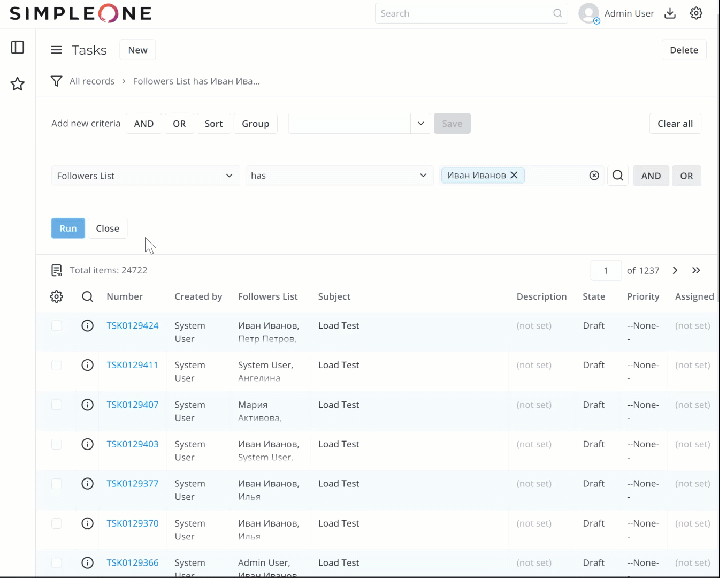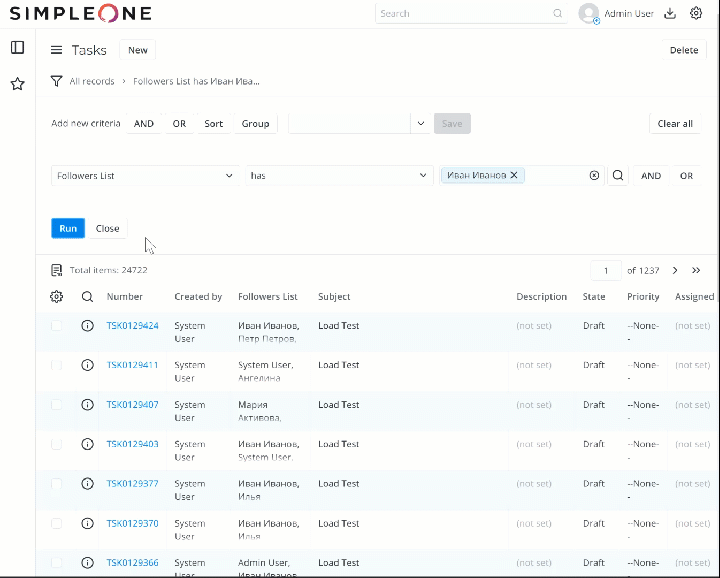
2 лайка
Тест на 790К записях
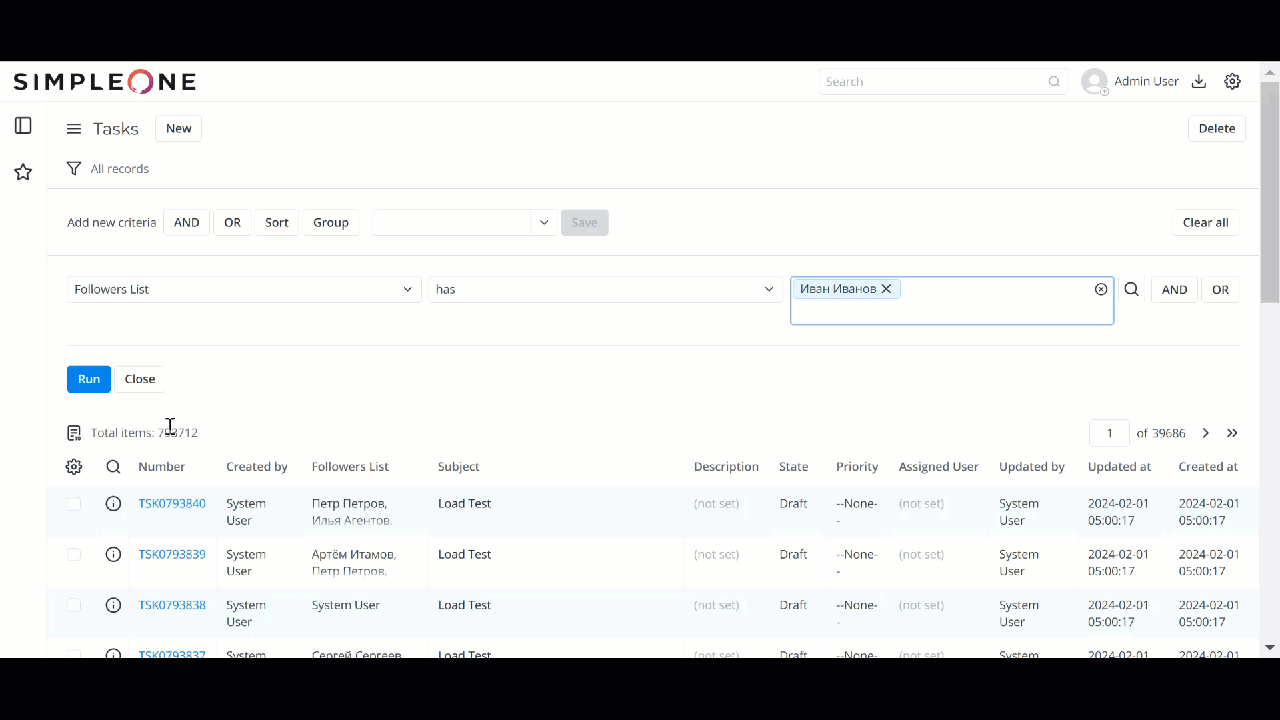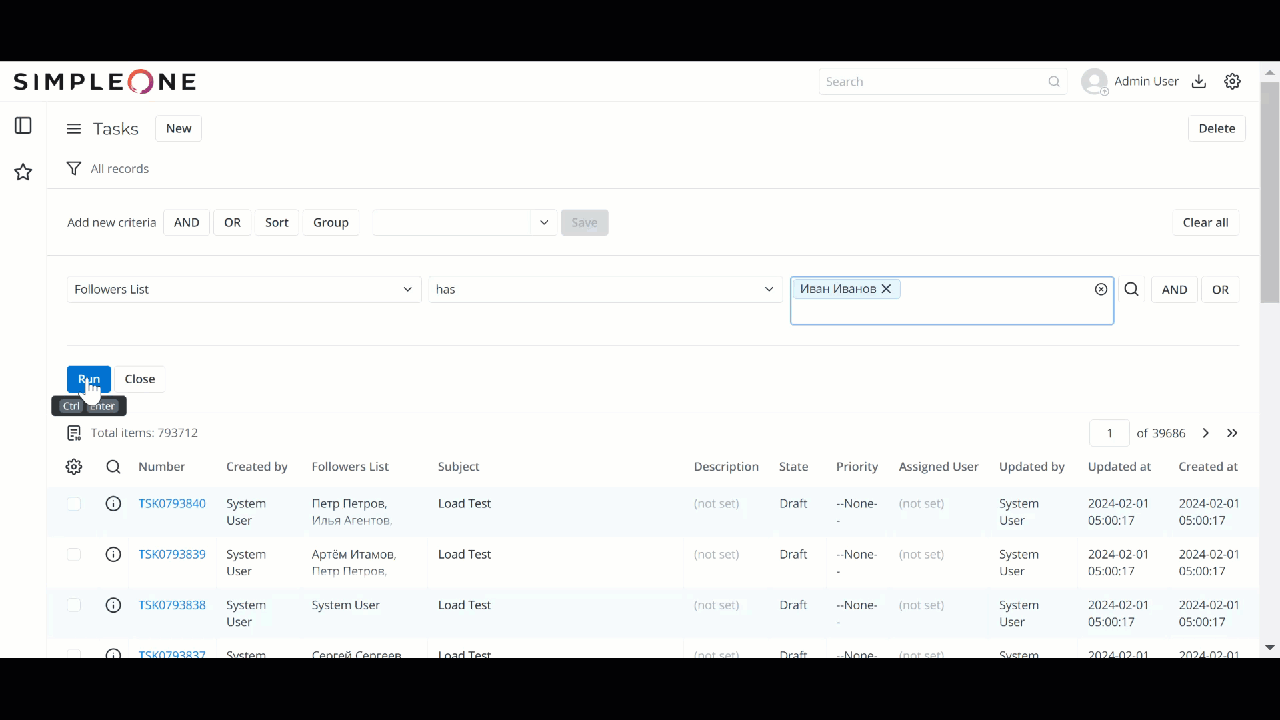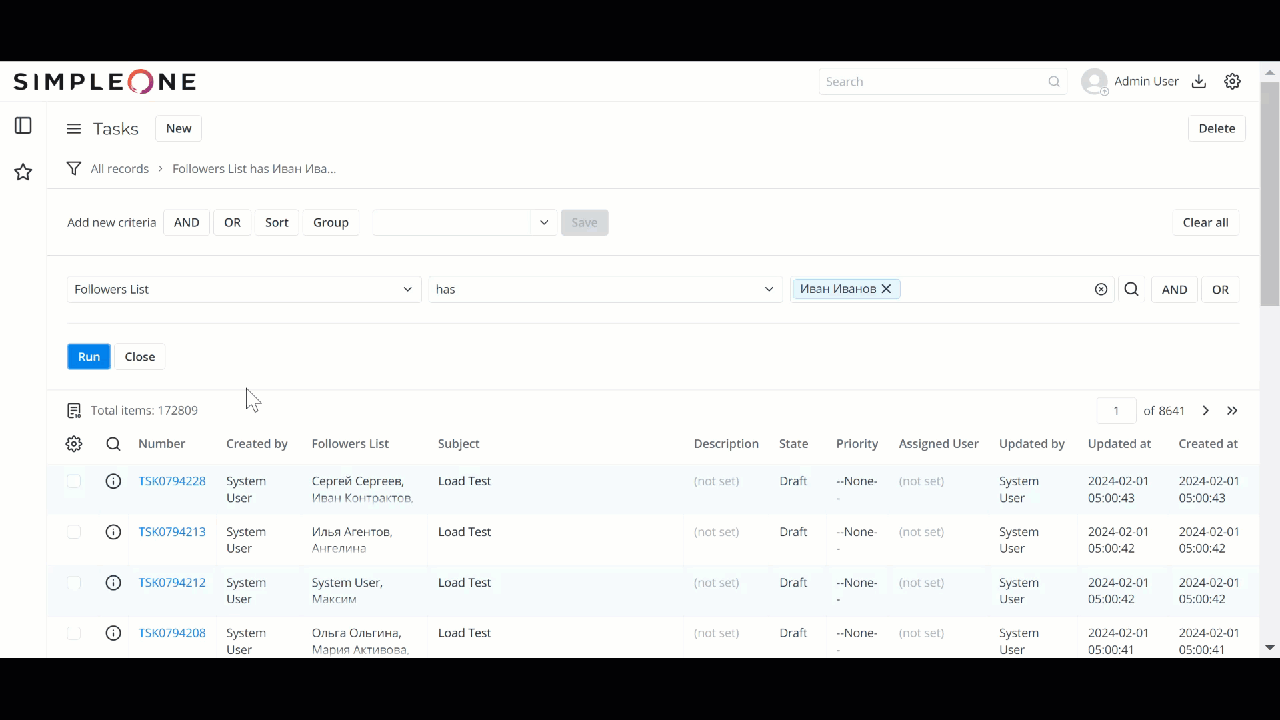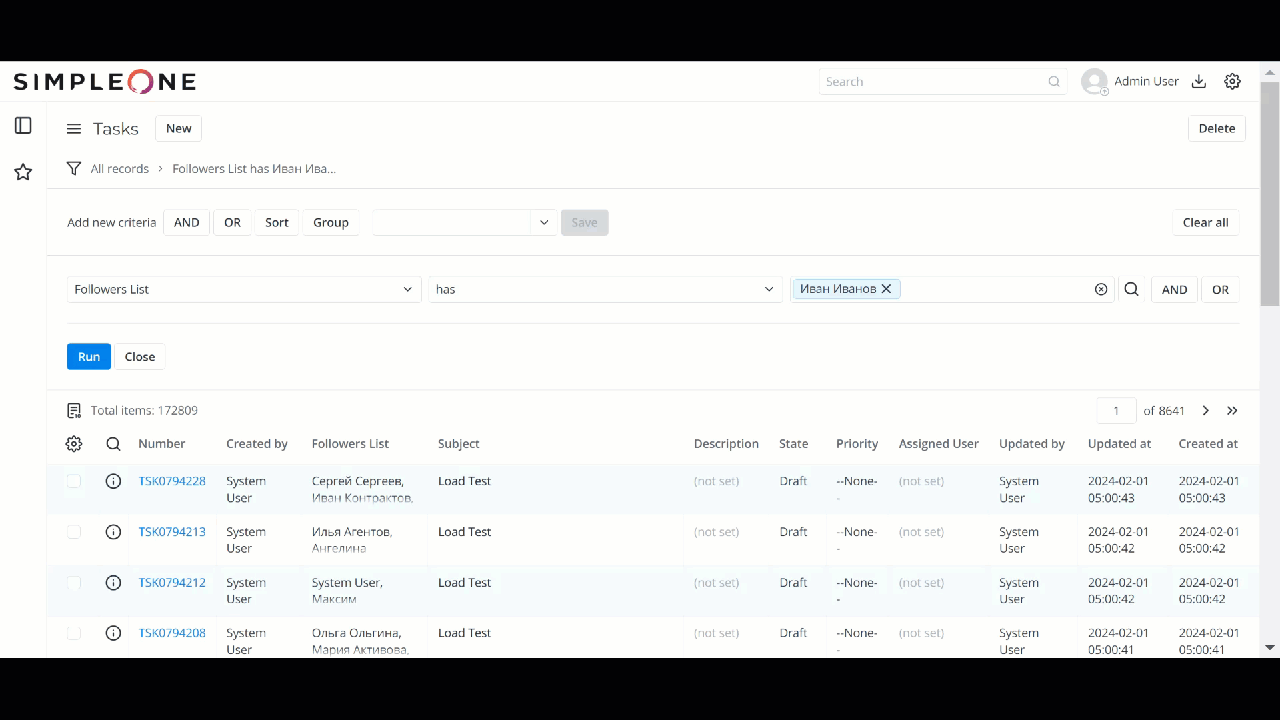
1 лайк
Андрей, мне удалось посмотреть через EXPLAIN поведение системы при фильтрации по List полю, на уровне SQL используется оператор LIKE по колонке типа text.
Действительно, делается скан таблицы. По поводу создания postgres SQL индекса Вам следует проконсультироваться с Customer Care, т.к. это вмешательство в работу платформы, что формально запрещено.
Как показали тесты выше, и без индекса шустро работает даже на большом количестве записей. Следует помнить также о том, что индексирование как таковое, особенно на часто меняющихся больших объемах данных, замедляет процедуры INSERT, UPDATE в таблицу. Так что за ожидаемый (небольшой) выигрыш по быстроте поиска нам придется заплатить чуть более медленными операциями INSERT, UPDATE.
Поскольку мы все же продолжаем пытаться фильтровать записи по List полю, рекомендую вернуться к первым постам в этой ветке и рассмотреть вариант с M2M таблицей или “гибридный” вариант, где все хранится в M2M таблице, а List поле постоянно “пересобирается” из нее.
С уважением, Никита
1 лайк
Большое спасибо за проведенный анализ и развернутый ответ.
1 лайк